Vision Transformer
이번 포스팅은 Vision Transformer에 대하여 알아보겠습니다.
Vision Transformer?
Vision Transformer(이하 ViT)는 2021년에 구글 리서치 팀에서 발표한 모델로 기존 NLP(Natural Language Processing, 자연어처리)에서 사용하던 Transformer 모델의 인코더 부분을 이미지처리에 적용한 것입니다. 기본 동작 구조는 BERT(Bidirectional Encoder Representations from Transformers)와 같습니다. 이미지 패치를 단어처럼 다루었다는 점이 핵심 내용이고, 동작 순서는 다음과 같습니다.

<동작 순서>
1. 이미지 패치화 : 이미지를 고정 크기로 작게 자름
2. 이미지 시퀀스화 : 왼쪽 상단부터 오른쪽 하단까지 순서대로 나열
3. 패치 벡터화 : flatten + linear projection
4. Embedding된 패치에 class 토큰과 위치 정보 추가
5. Transformer Encoder : Self-attention 연산
6. 마지막 MLP-Head(Multi-layer Perceptron Head)에서 class token을 이용하여 분류
기존의 Transformer Encoder는 LN(Layer Normalization, 층 정규화)를 MHA(Multi-Head Attention)연산 후에 진행했지만 ViT는 MHA연산 이전에 LN을 진행한다는 차이점이 있습니다. 연산전에 정규화를 진행함으로써 성능이 향상되었습니다.
ViT는 논문의 저자는 JFT-300M(약 3억장) 데이터 세트를 이용하여 Pre-Training을 한 모델을 ImageNet(약 128만장) 데이터 세트로 Transfer Learning(전이 학습) 또는 Fine-tuning을 하는 방법이 가장 좋은 성능을 나타냈다고 합니다. 즉, 거대한 데이터 세트로 선행학습을 하고, 그보다 작은 데이터 세트로 결과를 도출하는 것이 좋다는 것입니다. 이에 대한 장단점은 다음과 같습니다.
<장점>
1. 학습과정에서 이미지 한 장마다 발생하는 연산량이 적고, 학습 속도가 빠릅니다.
2. Transformer를 사용하여 파라미터 수에 제약이 없고, 모델 확장성이 좋습니다.
<단점>
1. 학습 데이터가 매우 많아야 합니다. 저자가 JFT-300M를 사용한 이유는 이보다 작은 데이터 세트로 학습을 진행할 경우 ResNet보다 성능이 낮은 결과를 보았기때문입니다.
2. 이미지 한 장마다 필요한 연산량은 줄었지만 엄청난 규모의 데이터 세트를 학습시키기때문에 ViT 모델의 학습은 많은 컴퓨팅 자원을 필요로 합니다.
ViT 이후 소개된 모델들
- 이 섹션에서는 ViT의 단점을 개선하여 소개된 여러 모델들 중 세 모델만 간략히 소개합니다.
- DeiT(Data-efficient Image Transformers)

페이스북 개발자들이 소개한 DeiT(Data-dfficient Image Transformers)는 JFT-300M의 거대한 데이터 세트로 학습을 진행해야 하는 단점을 개선하여 ImageNet만으로 학습을 진행 했습니다. 사용한 방식은 다음과 같습니다.
<주요 내용>
* Teacher-Student 기법 사용 : 전이 학습 방법 중 하나로, 교사모델이 학습한 것을 기반으로 학생 모델의 성능을 평가함
* Distillation token 추가 : class token과 같은 학습 가능한 벡터로 교사 모델이 예측한 label을 나타냄
* Class token과 Distillation token 값을 합쳐서 Prediction 결과가 나옴
- CaiT(Class-Attention in Image Transformers)
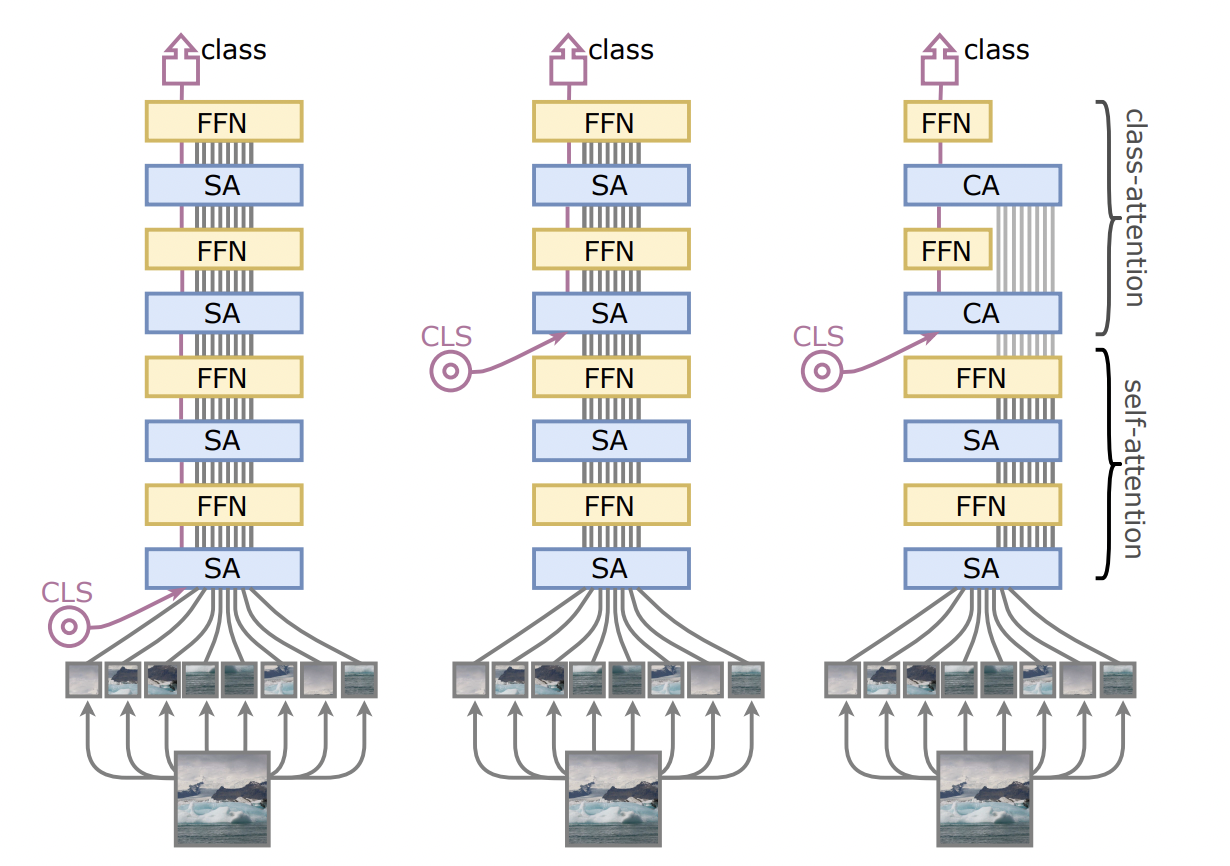 (left)기존 ViT 구조 (middle)class token의 위치를 중간으로 옮긴 구조 (right) CaiT 구조
(left)기존 ViT 구조 (middle)class token의 위치를 중간으로 옮긴 구조 (right) CaiT 구조
페이스북 Ai팀에서 DeiT와 같이 소개한 CaiT는 class token의 삽입 시기에 대한 연구를 진행했고, class token의 위치를 변형했을 때 성능이 향상된 점에서 처음 패치 임베딩에서 삽입을 하는 것 보다 self-attention 연산을 한 번 진행 한 후에 삽입을 하는 것이 성능을 향상 시킨다는 결론을 냈습니다. 이는 class token이 선형분류기에 쓰이는 유용한 분류 정보 요약을 더 잘했기때문이라고 합니다.
- T2T-ViT(Tokens-to-Token module Vision Transformer)
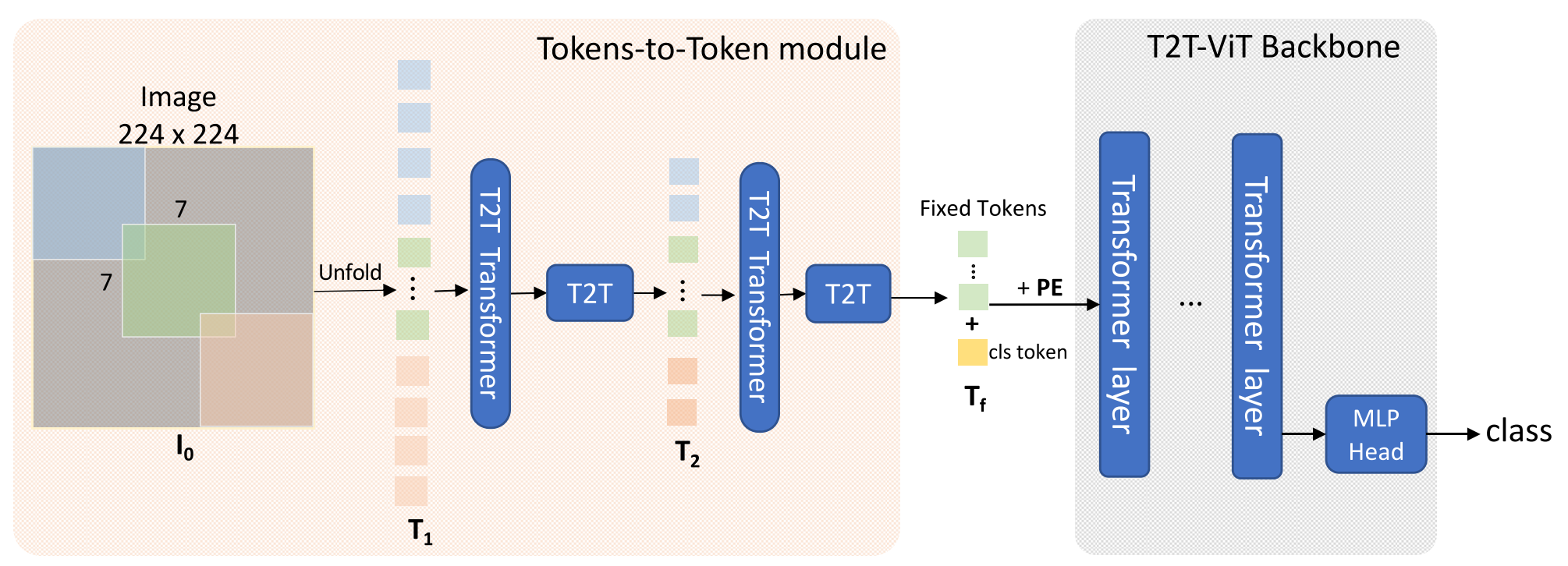
싱가폴의 한 연구팀에서 제시한 T2T-ViT는 거대한 데이터 세트를 사용해서 모델을 학습시켜야 하는 단점을 개선하기 위해 이 모델을 소개했습니다. 위 그림은 T2T-ViT의 구조를 나타낸 것인데, 기존 ViT에 Deep na T2T 모듈이 중요하므로 자세히 보겠습니다.
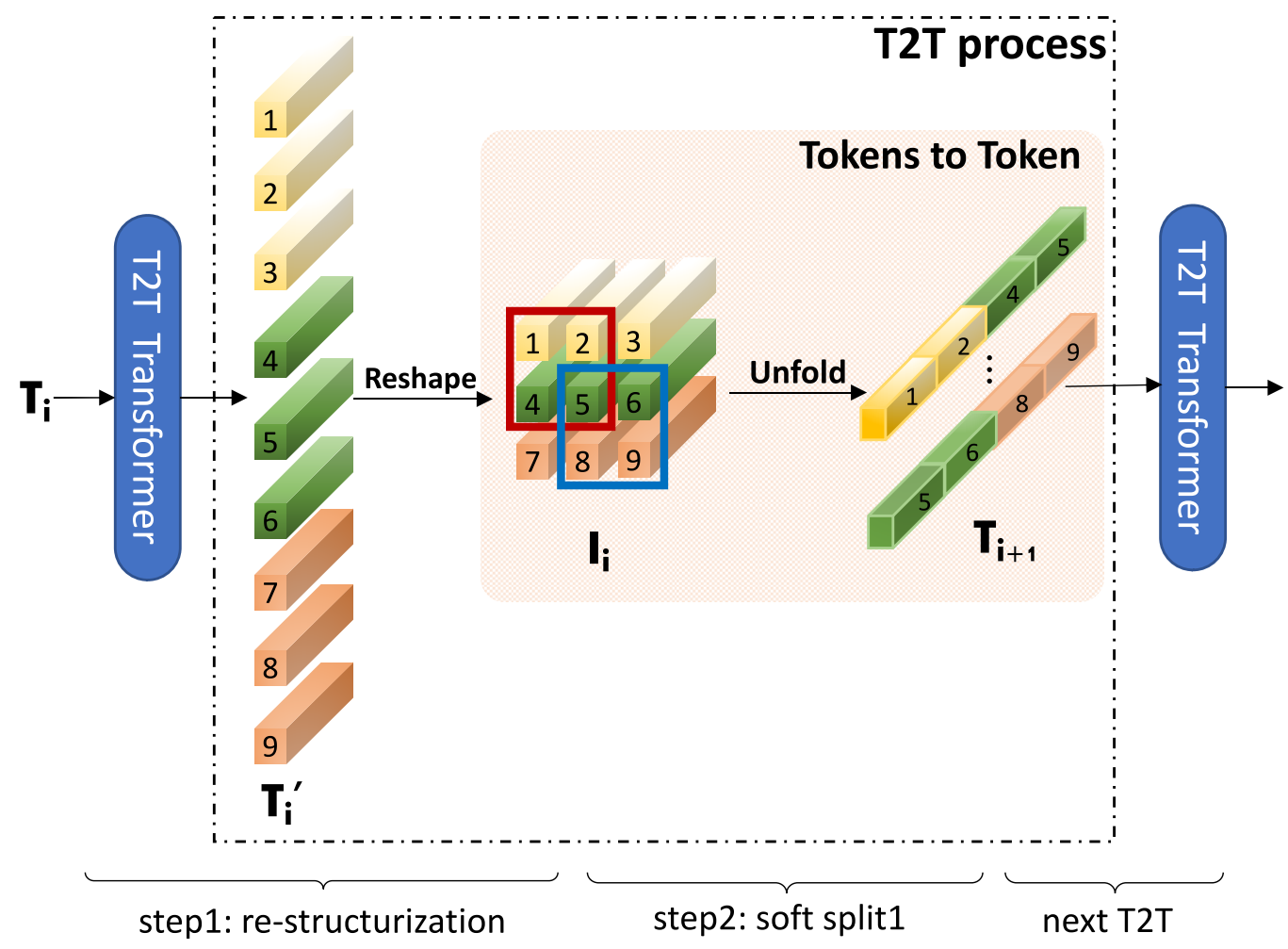
T2T 모듈은 토큰화 방식에서 기존 ViT와 차이가 있습니다.
< 기존 토큰화 방식 >
1. 이미지를 서로 겹치지않는 영역에서 패치로 나눔
2. 패치 토큰화
< T2T module >
1. 입력 시퀀스 → T2T module을 통과 → 동일한 크기의 시퀀스 출력
2. 2D 배열로 재구성
3. 이웃토큰끼리 연결(다음 단계의 입력 시퀀스)
그림을 예로 들면 처음 토큰화 했을 때는 9개의 토큰이 생성되고, T2T 모듈을 통과한 후에는 4개의 토큰이 생성됩니다. Reshape을 통해 특징을 잘 추출할 수 있으며, 토큰의 수가 줄었기때문에 연산량 또한 줄어듭니다.
SOTA 모델들의 성능 비교(참고용)

CaiT 논문에 명시된 성능 비교 표 입니다.
지금까지 ViT(Vision Transformer)에 대해 알아보았습니다. 여기서 포스팅을 마칩니다.
참고 문헌
{kind=link}