informer
본 포스팅은 Informer에 대한 내용입니다.
Informer 개요
- 트랜스포머 모델을 기반으로 긴 시퀀스 길이의 시계열 예측 모델을 제안
- 긴 시계열 데이터에 대해 효과적이고 빠르게 예측 할 수 있는 방법론 적용 1) ProbSparse Self-Attention 2) Self-Attention disitilling 3) Generative Style deocer
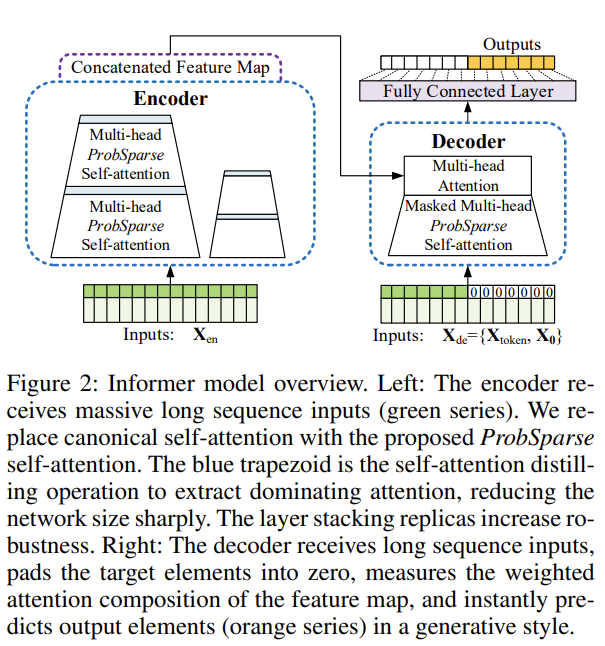
- 이미지 설명
- 왼쪽 : 인코더가 긴 시퀀스를 입력으로 받고 있는 그림이며, ProbSelf-Attention을 사용
- 파란색 사다리꼴 부분은 지배적인 Attention을 추출하고 크기를 줄이기 위한 목적으로 사용 됨
- 작은 사이즈의 복제된 인코더는 모델의 성능을 올리기 위한 역할
- 오른쪽 : 디코더가 긴 시퀀스를 입력으로 받아 예측 해야하는 타겟 부분은 0으로 패딩처리
- 인코더로부터 생성된 특징 맵과 함께 Attention을 수행하게 되어 한번에 예측
ProbSparse Self-Attention
- 확률 분포 기반으로 희소성을 측정하여 쿼리의 일부를 추출해 계산
- 확률 분포 방법은 KLD(Kullback-Leibler Divergence)사용
- KLD는 p(실제 값)와 q(예측 값)의 차이를 구하는 분포
Self-Attention Distilling
- 인코더 특징맵의 불필요한 정보 제거
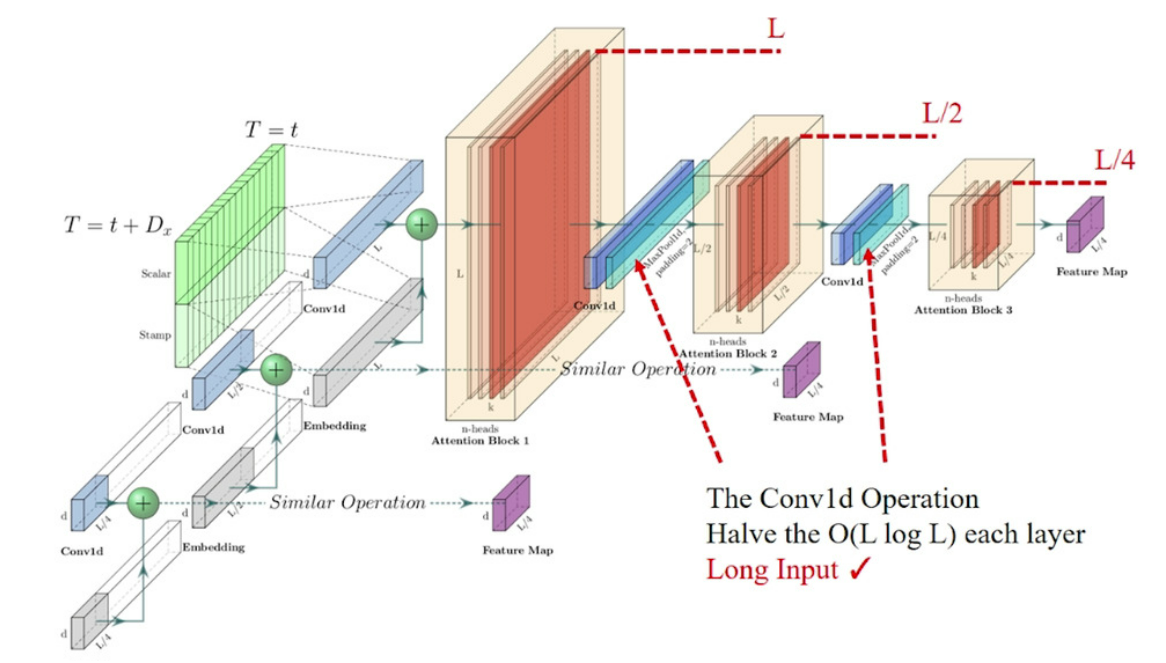
-
인코더의 성능을 올리기 위해 원래 인코더를 절반 크기로 복제 하여 최종적으로 모든 특징 들과 합침
Generative Style Decoder
- NLP에서 Generation Task를 수행할 때, Step-by-Step 추론과 같은 디코딩을 위해 Start Token을 사용
- 인포머에서의 Start Token은 디코더에 입력으로 주어지는 타겟의 일부 선행 정보이며, 추론 시 참조하는 대상
- 마지막 FC Layer를 추가하여 한번에 forward 하도록 설계
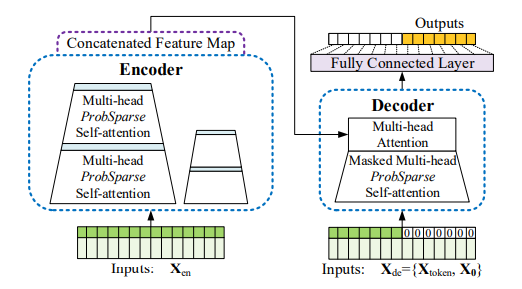
참고 문서