시계열 분석
본 포스팅은 시계열 분석에 대한 내용입니다.
시계열 분석이란
- 시계열 분석은 대부분 예측 과정에 많이 사용되지만, 과거의 행동을 진단하는 과정을 포함합니다.
- 한마디로 과거가 미래에 어떤 영향을 주는가? 에 대한 해답을 찾는 것이 목적입니다.
- 시계열 분석이 가장 광범위하게 사용되는 분야는 대표적으로 의학, 경제, 기상이 있습니다.
-
이 분양의 문제들은 시계열 분석의 목적과 일맥상통합니다.
-
의학 분야의 시계열 데이터 예시입니다.
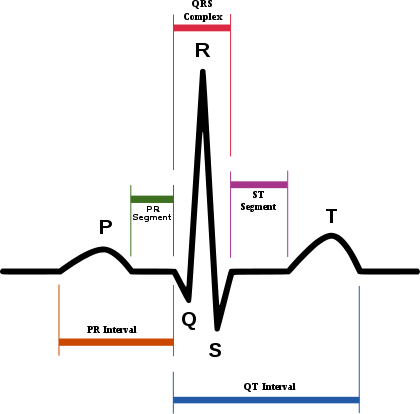
- 의학 분야는 1662년부터 시작하여 다양한 시계열 데이터가 축적되었고, 분석되었습니다.
- 그 중에서도 가장 성공적인 시계열분석의 대상은 바로 위 사진에 있는 ECG데이터 입니다.
- 이는 전기 신호를 통해 심장의 상태를 진단하는 기술로, 심장 상태 정보를 시계열적으로 표현합니다.
시계열 데이터의 구성요소
-
시계열 데이터의 구성요소는 세 가지로 구분됩니다. 1) 추세 : 장기적으로 증가하거나, 감소하는 경향성이 존재 2) 계절성 : 계절적인 요인의 영향을 받아 1년, 혹은 일정 기간 안에 반복적으로 나타나는 패턴 3) 주기성 : 정해지지 않은 빈도, 기간으로 일어나는 상승 혹은 하락
-
시계열 분해는 이런 시게열의 구성요소를 쉽게 파악할 수 있도록 도와줍니다.
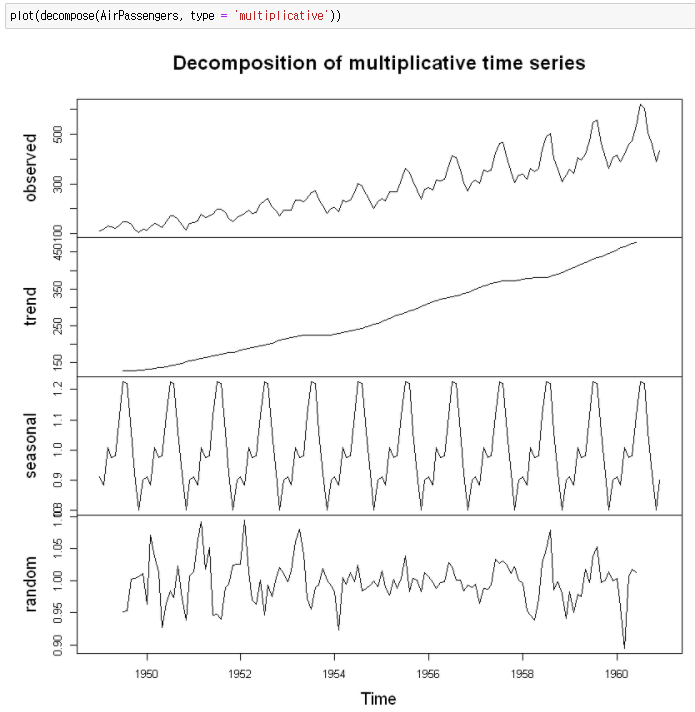
이러한 구성요소를 가진 대표적인 데이터 세트를 소개하고 이번 블로그 마치겠습니다.
ETTh1 Dataset
-
2016년 7월부터 2018년 7월까지 전기 트랜스포머(Electricity Transformer) 1곳에서의 데이터 입니다.
# 데이터셋 from darts.datasets import ETTh1Dataset df_ett1 = ETTh1Dataset().load().pd_dataframe() df_ett1 # 시각화 df_ett1.plot(figsize=(10,5), subplots=True)


Electiricity Dataset
- 한 가정 370곳에서 15분마다 전기 사용량을 측정한 데이터입니다.
-
데이터 행이 14만개, 컬럼이 370개인 매우매우 큰 다변량 데이터셋입니다.
# 데이터셋 from darts.datasets import ElectricityDataset df_elec = ElectricityDataset().load().pd_dataframe() df_elec.head() # 시각화 df_ett1.plot(figsize=(10,5), subplots=True) df_elec.iloc[10000:20000,:].plot(figsize=(10,5))


참고 문서